RCNN & Fast RCNN
In the series of posts, we will discuss about 2 stage object detectors Fast-RCNN, Faster-RCNN and their ideas. I will also give a brief introduction to RCNN but will not go into much detail.
2 stage detectors contains 2 stages for classifying and detecting objects. Typically, the first network will give the region proposals (the region where object might exist) and second network will take the region proposals as input and detects the object.
RCNN
RCNN contains 3 modules
- The first one generates the region proposal. This stage doesn’t use any neural network, but uses an algorithm called as selective search. Typically generates 2000 proposals for each image
- CNN which is used as feature extractor. The input to this is a region proposal (from above) and output is a vector (representing the region proposal).
- The third module is a linear SVM and bounding box regressor that wil take the feature vector from the above step and predict for each class.
Note : Whenever region proposal is mentioned, assume that it is rectangular. This rectangular is cropped from original image, then we do the processing on the smaller part.
FEATURE EXTRACTION
I will not discuss much about selective search (I don’t understand how that thing works). This algorithm generates usually 2000 proposals.
What I mean when I say generate is that for an input image, it will give us 2000 $(x, y, h, w)$ where $(x, y)$ denotes the top-left coordinate and $(h, w)$ denotes the height and width of proposal. The idea is that these location can have object in them. There are lot of algorithms that can do this task and selective search is one of them.
Assumming that we have region proposals, we resize them to (227, 227) and then passed to CNN network (Alexnet, vggnet etc) to get the vector representation of the proposal.
The feature extractor is usually pretrained on image-net and then finetuned on region proposals. The finetuning stage is called domain specific fine-tuning.
While finetuning, we remove the last layer of feature extractor (if its pretrained on image-net, we usually have it as 1000 neurons) and replace it with $(N+1)$ neurons where $N$ denotes the number of classes (+1 is for the background class).
One question should naturally come is how do we create training data for region proposals ?, how do we know what is ground-truth for any region proposal.
This question I will not answer here, but will discuss in detail in fast-rcnn.
OBJECT CATEGORY CLASSIFIER or LINEAR SVM
Once the feature extractor is trained, we train SVM’s for each class. The input to the SVM is the feature vector from above step (usually of size 4096)
Same question should occur here as well, how do we create training dataset for SVM ? I will skip the answer to this question.
Another question should occur is why are we using SVM ?. Anyway the feature extractor was trained using $(N+1)$ neurons as last layer, so it can tell for each proposal the class it belongs to.
Authors tried this and found that performance on VOC dropped from 54% to 50% on mAP. So they kept the idea of SVM (See appendix B of the paper for more details).
TESTING
The above section concludes on training. The following steps describe how the testing is done for an image in RCNN
- Run selective search on test image to get 2000 proposals. Resize all the proposals to shape (227, 227)
- Run the forward propogation for each proposal through finetuned CNN to get the extraced features (size 4096)
- Pass each feature to N SVM’s to get the scores and select the class with highest score. This way we will get predicted classes for all the proposals
- Per class bounding box regressor is used to predict the box co-ordinates (skipped this part)
- As the last step, we apply class wise nms (non maximum supression) to remove the overlapping proposals.
With this we close RCNN and move to Fast-RCNN
FAST RCNN
Fast RCNN was introduced to make RCNN fast (as name suggests) and also it performs better that RCNN
Before going I want to address some points
- I know that RCNN was not covered in detail. Anyone reading it for the first time may not understand the section of RCNN. The reason I wrote is just to familiarize yourself with the terminology.
- The reason I skipped important parts of RCNN is because I feel that they are not useful. Also from my point of view , RCNN is not a simple and direct model and has lot of complications. In simple words, it’s chaos.
- In terms of that fast rcnn is more simple and direct. Lot of back & forth steps from RCNN is removed.
Fast RCNN is created from RCNN, but it’s fast. RCNN takes 9.8 seconds per image while fast RCNN takes 0.1 seconds per image at test time (See table 4). Note that this 0.1 seconds is excluding the selective search proposal which usually takes 2 seconds per image.
One of the main reason why RCNN is slow is because feature extraction is done for each proposal. For example, if we have 100 proposals, then each proposal is cropped and passed to CNN for feature extraction. This is where fast-rcnn optimizes
The changes introduced by fast-rcnn are
- Introduces the ROI Pooling layer which will enable it to calcuate the feature vectors for all proposals at once.
- Removes SVM, both classification and regression are done using dense layer
- Proposes a 1 step training pipeline where both classification and regression loss is optimized compared to RCNN where classification and regression were trained seperately.
ARCHITECTURE
The architecure for fast-rcnn is given below
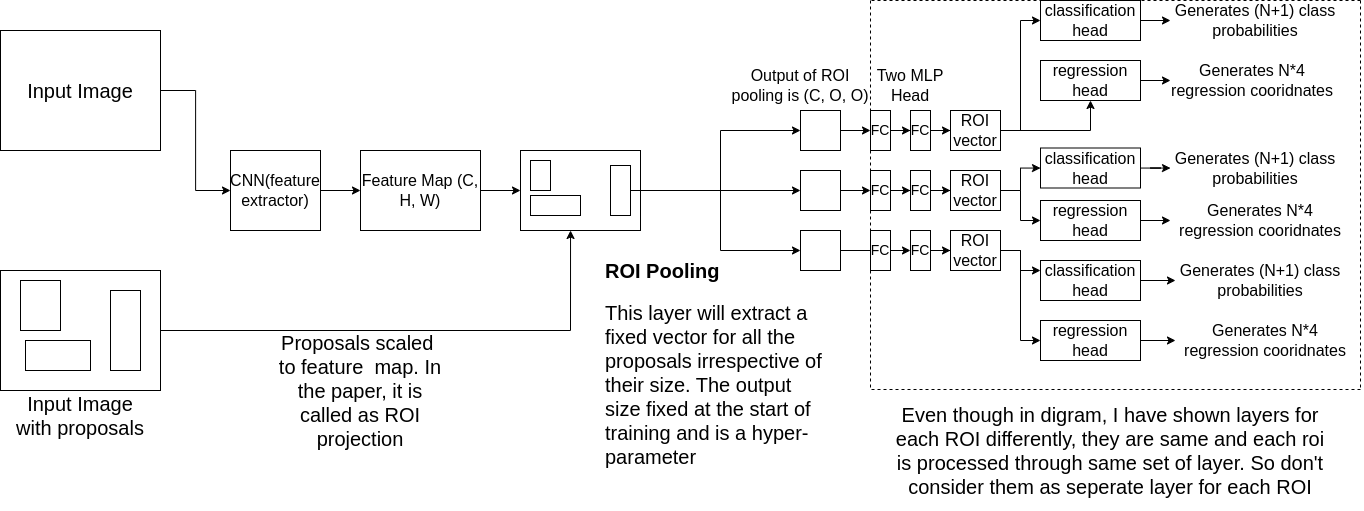
Points to observe
- Each proposal is projected to feature map and then a fixed size map is extracted using ROI pool layer
- As mentioned in the diagram, for each ROI, the output of ROIPool is passed to 2 MLP heads and then followed by classification and regression head
- One can calulate the regression and classification loss for each ROI at the time of training.
- If ROI Pooling is differentiable with respect to feature map, then doing backpropogation will update all the layers at once.
Let’s discuss each step in more detail.
- For the input image, we generate the proposals using the selective search algorithm (the one used by RCNN). As per the above diagram, we have 3 proposals.
- The image is first passed to a pretrained CNN (mostly trained on image-net). Let’s suppose the input image has shape $(3, H, W)$ and output of the feature extractor is $(C, H_{f}, W_{f})$
- Now the proposals are projected to feature map. That is if the proposal is at the location $(P_{x}, P_{y})$ on the original image and size is $(P_{h}, P_{w})$, then after the projection the proposal will be at location $(P_{x}\frac{W_{f}}{W}, P_{y}\frac{H_{f}}{H})$ on the feature map and the size will be $(P_{h}\frac{H_{f}}{H}, P_{w}\frac{W_{f}}{W})$
Note that projection is done for all the proposals. Also we have to do rounding as location and size should be integers. This rounding-off is something I am ignoring as of now.
Observe that projections are of different size (it is obvious as proposals are also different size). So simply cropping the feature map at the projection and then flattening will not work as they will not produce fixed size.
This is where ROI Pooling comes into play. This layer takes feature map and location of projection coordinates and then produces the fixed size feature map.
ROI POOLING LAYER
The ROI Pooling layer uses max pooling to convert feature map projection to a fixed size feature map. As per the example above, let’s say the projection of feature map will be
\[(C, P_{h}\frac{H_{f}}{H}, P_{w}\frac{W_{f}}{W})\]where $C$ is channels. Then this input will be transformed to $(C, O, O)$ where $O$ is the layer hyper-parameter that are independent of the proposal. This value is fixed at the start of training, and the common value is 7.
Also ROI Pooling is appiled to each channel and that is how we will get $C$ channels in the output. Now the big question is how do we calculate output for one channel?
We know that height and width of projection is ($P_{h}\frac{H_{f}}{H}, P_{w}\frac{W_{f}}{W}$). Using this we have to create an output of $(O, O)$. So what we do is divide the projection into sub windows each of size ($P_{h}\frac{H_{f}}{HO}, P_{w}\frac{W_{f}}{WO}$) and in each subwindow we will take the maximum.
Let’s take an example given the image below. We have a image of (8, 8) and feature map of (4, 4). As shown in the diagram, the proposals are at (0, 0) and (2, 3). The diagram shows how ROI pooling layer works. The shaded lines on the second proposal are sub-windows. In each subwindow, we take the maximum value.
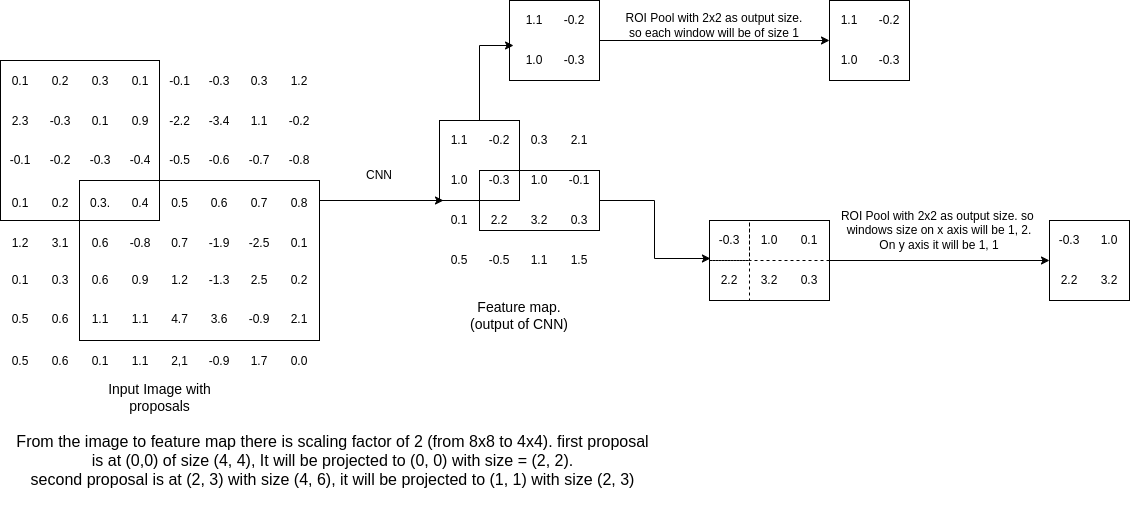
As shown in the diagram, the sub window sizes are calculated and rounded off to nearest integer. In case of second proposal, the first window size can be 2 as well.
Note
- Because of rounding, it is possible that sub windows will not be of same size.
- The sub window calculation is applied to each channel as mentioned before also.
- There are some corner cases which I don’t have complete understanding. For example if the projection is of (5, 1) that is height 5 and width 1. Let’s suppose the ROI pool output size is (3, 3) then how do we create subwindows here ?
- This blog gives an example. I suggest you can visit that to get more familiarity.
- This operation is available in pytorch via
torchvision.ops.roi_pool. So you can play with that as well to get more understanding. - I also tried reading source code to understand more of corner cases, but no luck there as well.
Now that ROI Pooling is done, the last steps remain is to calculate the class probabilities and bounding box co-ordinates.
Output of ROI Pooling is calculated for each proposal, flattened and then they are passed to series of FC layers to get vector representing each proposal. This vector is then passed to two FC’s layers
- First one has $(N + 1)$ as the output size where $N$ denotes the number of classes and $1$ is for background class. Applying softmax will give us class probabilties.
- Second one has $4N$ as the output size. These denote the bounding box coordinates for each class (they are not exactly coordinates). For backgroound class, we will not predict the box coordinates which is obvious.
One question can arise is why are we predicting the bounding box co-ordinates ? For each proposal, we have the location and why can’t we use that location as our predicted box coordinates ?. That is, why can’t we say proposal co-ordinates is my bounding box prediction ?
This is a valid question and the reason is the proposals co-ordinates are usually not that accurate. Having a bounding box regressor usually improves the score. But we don’t discard the proposal co-ordinates totally. We use them as the base and then only predict the offsets. Then the final predicted box co-ordinates can be written as function of $f(proposal, offset)$. More details are given below
With this we conclude forward pass for a single image in fast-rcnn
TRAINING
Given that we have an idea of how forward pass works for fast-rcnn, then obivous next question should be how to train the model ?
Before that I want to remind once again that we have training data which contains images with ground truth. The ground truth is set of rectangular boxes and each box has a label assigned to it.
The first step is to generate the proposals for all the training images.
Model training for fast-rcnn is done by optimizing a joint loss which is combination of classficiation and regression loss. Loss is calculated for each proposal and then averaged. So to calulate loss for each proposal, we should compare the proposal with something. That is for example, if 2000 proposals are generated then usually lot of them are not useful. That is proposals doesn’t contain any object in them. So the model should assign the background class probability for these proposals a very high value.
So in the sense, using training data (image, ground truth, proposals generated on training data) we should create $(X_{p}, y_{p}, b_{p})$ where $X_{p}$ is the proposal, $y_{p}$ is ground truth class assigned to the proposal. It can be background or one of the $N$ classes. $b_{p}$ is bounding box co-ordinates assigned to that proposal.
The way to do this is as follows
- For a proposal, if the maximum IoU with all of the ground truths box is greater than 0.5, then we call it as positive proposal. If there are multiple such ground truths, then the one with the highest IoU is chosen and assigned to the proposal. This means if $gt$ is ground truth assigned to proposal $p$, then our pair becomes $(X_{p}, y_{gt}, b_{gt})$ where $y_{gt}$ is the ground truth class of $gt$ and $b_{gt}$ is the ground truth bounding box co-ordinates.
- For a proposal, if the maximum IoU with ground truth is in the interval $(0.1, 0.5]$, then these proposals are called as negative proposal. They have $y_{p}$ as background class and no box coordinates.
- The remaining proposals are ignored.
Now that we have $(X, y, b)$ we will discuss how to calculate the loss function.
Classification loss is simply the cross-entropy between predicted probabilties and ground truth for that proposal (It will be over $N + 1$ outputs).
The second part is regression loss. This layer predicts the offsets that when added to proposal will give the ground truth box. That is denote the proposal box as $(P_{x}, P_{y}, P_{w}, P_{h})$ and ground truth box as $(G_{x}, G_{y}, G_{w}, G_{h})$ where subscript $x, y$ denote the center coordinates. The proposal co-ordinates are usually given by region proposal algorithm (here it will be selective search).
We then define the offsets as $(dx, dy, dw, dh)$ as follows
\[G_{x} = P_{w}dx + P_{x}\] \[G_{y} = P_{y}dy + P_{y}\] \[G_{w} = P_{w}e^{-dw}\] \[G_{h} = P_{h}e^{-dh}\]So instead of predicting $(G_{x}, G_{y}, G_{w}, G_{h})$ we predict $(dx, dy, dw, dh)$ for the regression FC layer.
Let’s suppose the predictions are $(t_{x}, t_{y}, t_{w}, t_{h})$ then we define the regression loss as
$L_{R}(t, d) = \sum\limits_{i \in {x, y, w, h}} f_{s}(t_{i} - d_{i})$
where $f_{s}$ is defined as
\[f_{s}(x) = \begin{cases} 0.5x^2 & \text{if $\lvert x \rvert < 0.5$ } \\ \lvert x \rvert - 0.5 & \text{otherwise} \end{cases}\]With this we can define loss function for a proposal is
\[L = \begin{cases} L_{C}(p, y_{gt}) + \lambda L_{R}(t, d) & \text{if proposal is positive} \\ L_{C}(p, ,y_{gt}) & \text{if proposal is negative} \end{cases}\]Authors used $\lambda = 1$ in the implementation. Final loss function is average over all the proposals.
MINI BATCH SAMPLING
In each iteration, 2 images are chosen uniformly. For each image, 64 proposals are chosen randomly. In 64 proposals, 25% are positive proposals and 75% are negative proposals. Usually SGD as the optimizer works well.
Another important point to note is that the pretrained model (for example resnet), batch normalization is turned off in training phase (because we use 2 images per batch, so training is unstable if we don’t turn it off).
This concludes the training part.
TESTING
The following steps describe how the testing is done for an image
- Run the selective search on the image to get 2000 proposals.
- Pass the image to CNN network to get the feature map. Calculate the ROI Pooling output for all the proposals.
- Pass the pooling output to get class probability and bounding box co-ordinates. The confidence score for the box is the probability score.
- Perform the non maximum supression for each class separately using the confidence scores.
CONCLUSION
In this we discussed RCNN and Fast RCNN. Although I didn’t discuss much on backpropogation of ROI Pooling layer, you can assume that the Pooling layer is differentiable with respect to feature map and not with respect to proposals (due to rounding).
I do have some vague understanding of backprop for ROI Pool, but expressing it in words is becoming difficult. (let’s just say I didn’t understood it totally.)
One more point to note that is that people don’t usually train fast rcnn (I never trained one) and usually go ahead with faster rcnn and its variant. This kind of builds the base for understanding of faster rcnn.